เลือก GPU Serverสำหรับเทรน
และรัน AI อย่างไรให้คุ้มค่า
จาก POC สู่ Production
Introduction
AI ไม่ได้เริ่มต้นที่โมเดลเพียงอย่างเดียว แต่เริ่มจาก “โครงสร้างพื้นฐาน” ที่เหมาะสม หากเลือก GPU เล็กเกินไป โมเดลอาจรันไม่ได้หรือเทรนช้าเกินใช้งานจริง หากเลือกสเปกสูงเกินความจำเป็น ต้นทุนก็จะสูงโดยไม่สร้างผลลัพธ์เพิ่มขึ้น
ดังนั้นการเลือก GPU Server สำหรับ AI ควรมองทั้งขนาดโมเดล, VRAM, จำนวน GPU, CPU, RAM, Storage, Network, ความปลอดภัยของข้อมูล และความสามารถในการขยายระบบในอนาคต
ReadyIDC วางบริการ GPU VPS และ GPU Server สำหรับองค์กร นักพัฒนา ทีม AI/ML ทีม Data และธุรกิจที่ต้องการใช้พลังประมวลผล GPU โดยไม่ต้องลงทุนซื้อเครื่องเอง ไม่ต้องดูแลค่าไฟ ระบบระบายความร้อน Hardware Maintenance หรือ Data Center เอง
จุดเด่นของบริการ GPU VPS คือการใช้ GPU Passthrough เพื่อให้ Virtual Machine เข้าถึง GPU ได้โดยตรง ใกล้เคียง Bare Metal ในส่วนของบริการ GPU Server มอบ Dedicated GPUs No Sharing ให้คุณใช้งานได้เต็มประสิทธิภาพ เหมาะกับงาน AI Training, Inference, Cloud Workstation, Emulator, Gaming, Live Streaming และงานประมวลผลหนักต่อเนื่อง
ReadyIDC GPU VPS และ GPU Server เหมาะกับใคร
บริการของ ReadyIDC เหมาะกับผู้ใช้งานหลายกลุ่ม ได้แก่
- AI Developer, ML Engineer
- team R&D, team Data, team Enterprise
- งาน Emulator/Automation
- Live Streaming
- Video Production
- Designer
- 3D Artist
- HPC/Data Processing workload
เปรียบเทียบขนาด LLM กับ Package GPU VPS และ GPU Server ของ ReadyIDC
การเลือก GPU Server สำหรับงาน LLM ควรเริ่มจาก “ขนาดโมเดล” และ “วิธีรันโมเดล” ก่อนเสมอ GPU ที่ “แรงที่สุด” อาจไม่ใช่คำตอบเสมอไป เพราะงาน LLM แต่ละระดับต้องการทรัพยากรต่างกันอย่างชัดเจน ตั้งแต่โมเดลขนาด 1B–7B สำหรับการทดลองและ RAG เบื้องต้น ไปจนถึง 70B–100B+ สำหรับ Private LLM, Long Context, Batch Inference และงาน AI ระดับองค์กร
ตารางเปรียบเทียบขนาด LLM กับ Package ReadyIDC
| Package / GPU | ขนาด LLM ที่เหมาะ | คำแนะนำ |
|---|---|---|
| RTX 3050 6GB | 1B–3B แบบ quantized | เหมาะกับลูกค้าที่ต้องการเริ่ม Dev/Test หรืองาน AI เบื้องต้น ต้นทุนต่ำ |
| RTX 5060 Ti 16GB | 3B–7B | จุดเริ่มต้นที่ดีสำหรับ RAG, chatbot, Ollama, LM Studio และ 7B quantized |
| RTX 3090 24GB | 7B สบายขึ้น, 13B แบบ quantized | เหมาะกับลูกค้าที่เริ่มเข้าสู่ LLM จริงจัง ต้องการ VRAM มากกว่า 16GB |
| RTX 5090 32GB | 13B ดีขึ้น, 30B–34B แบบ quantized บางกรณี | เหมาะกับงาน LLM + AI Image/Video ที่ต้องการพลังประมวลผลสูงขึ้น |
| RTX PRO 5000 Blackwell 48GB ECC | 30B–34B quantized, 13B production | เหมาะกับองค์กรที่ต้องการความเสถียร VRAM สูง และใช้ระบบต่อเนื่อง |
| RTX PRO 6000 Blackwell 96GB ECC | 70B quantized, 34B long context/high concurrency | เหมาะกับ private LLM, vLLM 70B+, inference production และงาน AI ระดับองค์กร |
| Dual GPU: 2 × RTX 5060 Ti 2*16GB | หลาย service ขนาด 7B หรือ 7B แบบ sharding | เหมาะกับลูกค้าที่ต้องการแยก workload หลายตัว หรือต้องการ throughput เพิ่ม |
| Dual GPU: 2 × RTX 3090 2*24GB | 13B production, 30B แบบ sharding | เหมาะกับทีม AI ที่ต้องการทดลอง multi-GPU และรันหลายโมเดลพร้อมกัน |
| Dual GPU: 2 × RTX 5090 2*32GB | 30B–34B, 70B 4-bit แบบ sharding | เหมาะกับงาน inference หนักขึ้น หรือ batch workload |
| Dual GPU: 2 × RTX PRO 5000 2*48GB | 70B 4-bit/8-bit แบบ tensor parallel | เหมาะกับลูกค้าที่ต้องการรันโมเดลใหญ่ แต่ยังไม่ถึงระดับ 4–8 GPU |
| Dual GPU: 2 × RTX PRO 6000 2*96GB | 70B production, 100B+ quantized | เหมาะกับ enterprise private LLM, long context และ concurrent users จำนวนมาก |
| GPU Server 4–8 ใบ ขึ้นกับรุ่น GPU | 70B+, 100B+, multi-model, distributed workload | เหมาะกับ production AI, fine-tuning ขนาดใหญ่, batch inference, render farm และงานองค์กรที่ต้องการขยายระบบ |
สำหรับผู้เริ่มต้น สามารถเริ่มจาก GPU VPS หรือ GPU Server รุ่นที่เหมาะกับโมเดล 7B–13B เพื่อทดลองระบบ RAG, Chatbot, Ollama, LM Studio หรือ Fine-tuning แบบ LoRA/QLoRA ได้ก่อน เมื่อ workload เติบโตขึ้น จึงค่อยขยับไปยัง RTX 5090, RTX PRO 5000 Blackwell หรือ RTX PRO 6000 Blackwell เพื่อรองรับโมเดลขนาดใหญ่ขึ้น จำนวนผู้ใช้งานพร้อมกันมากขึ้น และ context length ที่ยาวขึ้น
สำหรับองค์กรที่ต้องการรันโมเดลขนาดใหญ่ เช่น 70B, 100B+ หรือมี workload หลายชุดพร้อมกัน ReadyIDC สามารถออกแบบ GPU Server แบบ Multi-GPU ได้สูงสุด 8 ใบต่อเครื่อง เพื่อรองรับการทำงานแบบ Scale-up ไม่ว่าจะเป็น LLM Inference, Private AI, Distributed Fine-tuning, Batch Processing, Render Farm หรือ AI Production Workload ที่ต้องการประสิทธิภาพสูงและความต่อเนื่องในการใช้งาน
GPU Server สูงสุด 8 ใบต่อเครื่อง: เหมาะกับงานแบบใด
การเพิ่ม GPU สูงสุด 8 ใบต่อเครื่องเป็นข้อได้เปรียบสำคัญสำหรับงานที่ต้องการ throughput หรือ VRAM รวมสูงขึ้น แต่ต้องเข้าใจว่า VRAM รวมของหลาย GPU ไม่ได้กลายเป็น VRAM ก้อนเดียวโดยอัตโนมัติ
ตัวอย่างเช่น เครื่อง 8 × RTX PRO 6000 Blackwell อาจมี VRAM รวมเชิงกายภาพสูงมาก แต่การใช้โมเดลเดียวให้กระจายข้าม GPU ต้องอาศัย software เช่น DeepSpeed, FSDP, Megatron-LM, Tensor Parallelism, Pipeline Parallelism หรือ vLLM Tensor Parallel หาก software ไม่รองรับ การ์ดแต่ละใบจะทำงานแยกกันมากกว่าจะรวมเป็นหน่วยความจำเดียว
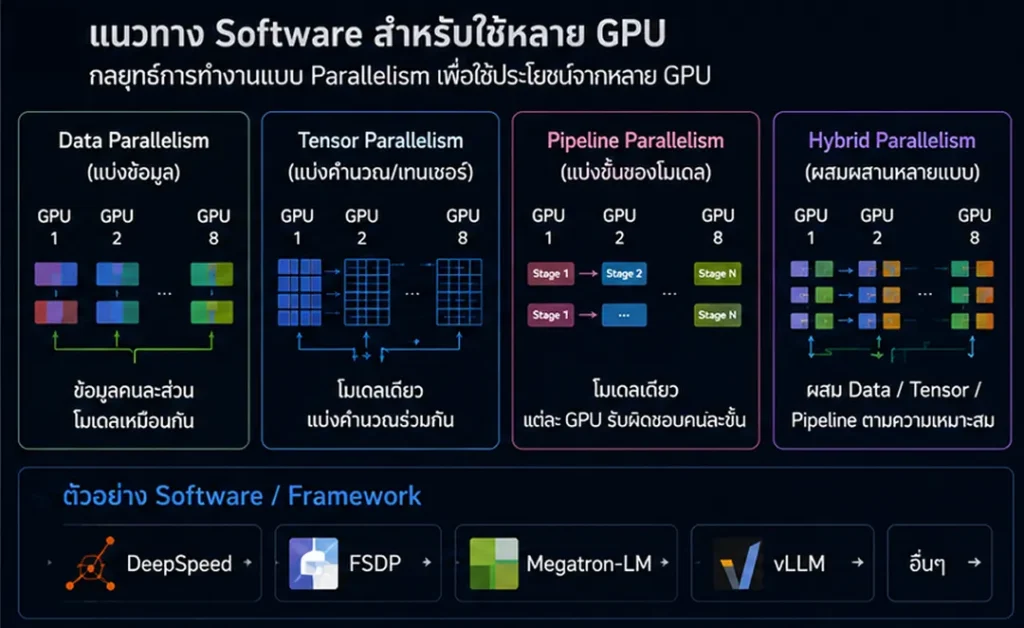
ตารางวิธีเลือก Package จากกรณีใช้งาน
| กรณีใช้งาน | วิธีเลือก |
|---|---|
| รันหลายโมเดล / หลาย service พร้อมกัน | เลือก Multi-GPU เพื่อแยก workload เช่น GPU ใบที่ 1 รัน chatbot, ใบที่ 2 รัน embedding หรือ image generation |
| รันโมเดลเดียวที่ใหญ่เกิน GPU ใบเดียว | เลือก Dual GPU หรือ 4–8 GPU พร้อม framework ที่รองรับ tensor parallel / pipeline parallel |
| เพิ่มจำนวนผู้ใช้งานพร้อมกัน | เลือก GPU ที่ VRAM สูงขึ้น หรือเพิ่ม GPU เพื่อรองรับ KV cache และ batch concurrency |
| เพิ่ม context length เช่น 32K, 64K, 128K | ควรขยับ package ขึ้น 1–2 ระดับ เพราะ KV cache จะใช้ VRAM เพิ่มมาก |
| Fine-tuning | LoRA/QLoRA ใช้ทรัพยากรน้อยกว่า full fine-tuning มาก แต่ควรเลือก VRAM เผื่อมากกว่า inference |
| Full training / pretraining | ไม่ควรประเมินจากตารางนี้โดยตรง ต้องออกแบบเป็น project เฉพาะ |
จุดแข็งเชิงกลยุทธ์ของ ReadyIDC สำหรับงาน AI
1. ลดต้นทุนเริ่มต้น ไม่ต้องลงทุนซื้อ Hardware เอง
การซื้อเครื่อง GPU Server เองมีต้นทุนสูงกว่าราคา GPU เพราะต้องรวมค่าเครื่อง, CPU, RAM, NVMe, Power Supply, Rack, Network, ค่าไฟ, Cooling, อะไหล่สำรอง และคนดูแลระบบ ReadyIDC ช่วยให้ธุรกิจเริ่มต้นใช้ GPU ได้เร็วขึ้นโดยไม่ต้องลงทุน CapEx ก้อนใหญ่ Fast Start คือเปิดใช้งาน GPU ได้รวดเร็ว ลดการลงทุน Hardware ราคาแพง และลดค่าใช้จ่ายแฝง เช่น ค่าไฟ, Cooling และ Maintenance.
2. GPU Passthrough ให้ประสิทธิภาพใกล้ Bare Metal
GPU Passthrough แตกต่างจาก Shared GPU หรือ vGPU เพราะให้ GPU แบบ Dedicated กับ VM เพียงเครื่องเดียว เหมาะกับงาน AI Training, Deep Learning, Rendering และ Compute หนักที่ไม่ควรแย่งทรัพยากรกับผู้ใช้อื่น GPU Passthrough ให้ GPU แบบ Dedicated กับ VM ทำให้ได้ประสิทธิภาพสูงและ latency ต่ำกว่าแนวทาง shared GPU สำหรับงาน AI training หรือ compute หนัก
3. Data Center ในประเทศไทย ลด latency และตอบโจทย์ข้อมูลภายในประเทศ
สำหรับองค์กรไทย งาน AI จำนวนมากเกี่ยวข้องกับข้อมูลลูกค้า เอกสารภายใน เสียงสนทนา ภาพจากกล้อง หรือข้อมูลธุรกิจ การให้บริการจาก Data Center ในประเทศไทยช่วยลด latency และช่วยให้การจัดการ data residency ชัดเจนขึ้น ReadyIDC ระบุว่าข้อมูลถูกจัดเก็บและประมวลผลภายในประเทศไทยโดยไม่มีการถ่ายโอนข้อมูลไปต่างประเทศ รวมถึงมี Data Center ระดับ Tier 3, ระบบไฟและเครือข่ายแบบ Redundant, SLA 99.95% ตามเงื่อนไข และทีม support 24/7
4. ขยายจาก POC ไป Production ได้
หลายโครงการ AI เริ่มจากเครื่องเล็ก เช่น GPU 1 ใบ เพื่อทดสอบโมเดล จากนั้นเมื่อระบบเริ่มมีผู้ใช้งานจริงจึงต้องเพิ่ม VRAM, เพิ่ม GPU, เพิ่ม Storage หรือแยกเครื่อง inference ออกจากเครื่อง training การมีทั้ง GPU VPS และ GPU Server ทำให้ ReadyIDC สามารถวางเส้นทางการเติบโตได้ตั้งแต่ POC, MVP, Fine-tuning, RAG, Inference Production ไปจนถึง Multi-GPU Server
เริ่มต้น AI Infrastructure ได้ง่ายกว่า โดยไม่ต้องลงทุนซื้อ Hardware เอง
ไม่ต้องดูแล Data Center, ค่าไฟ, Cooling และ Maintenance แต่ยังสามารถเลือกทรัพยากร GPU ให้เหมาะกับงานจริงได้ ตั้งแต่การทดลอง POC ไปจนถึงระบบ Production ระดับองค์กร
หากยังไม่แน่ใจว่าควรเลือก GPU รุ่นใดหรือจำนวนกี่ใบ ทีม ReadyIDC สามารถช่วยประเมินจากโมเดลที่ต้องการใช้ ขนาดข้อมูล จำนวนผู้ใช้งานพร้อมกัน และเป้าหมายของระบบ เพื่อแนะนำ GPU VPS หรือ GPU Server ที่เหมาะสมที่สุดสำหรับงาน AI ของคุณ
สำรวจบริการ AI Infrastructure ของเรา

GPU VPS
เพิ่มศักยภาพการประมวลผลสำหรับ AI Training, Cloud Workstation, Emulator, Gaming และ Live Streaming ด้วยพลัง GPU Passthrough ประสิทธิภาพระดับ Bare Metal

GPU Servers
Dedicated GPU Servers Bare Metal GPU Infrastructure สำหรับ AI Training, Inference และ High Performance Compute Workloads
Scale without limits on the infrastructure that grows with you
โครงสร้างพื้นฐานดิจิทัลระดับองค์กรที่ยืดหยุ่น ปลอดภัย และพร้อมสเกลทันทีเมื่อธุรกิจเติบโต